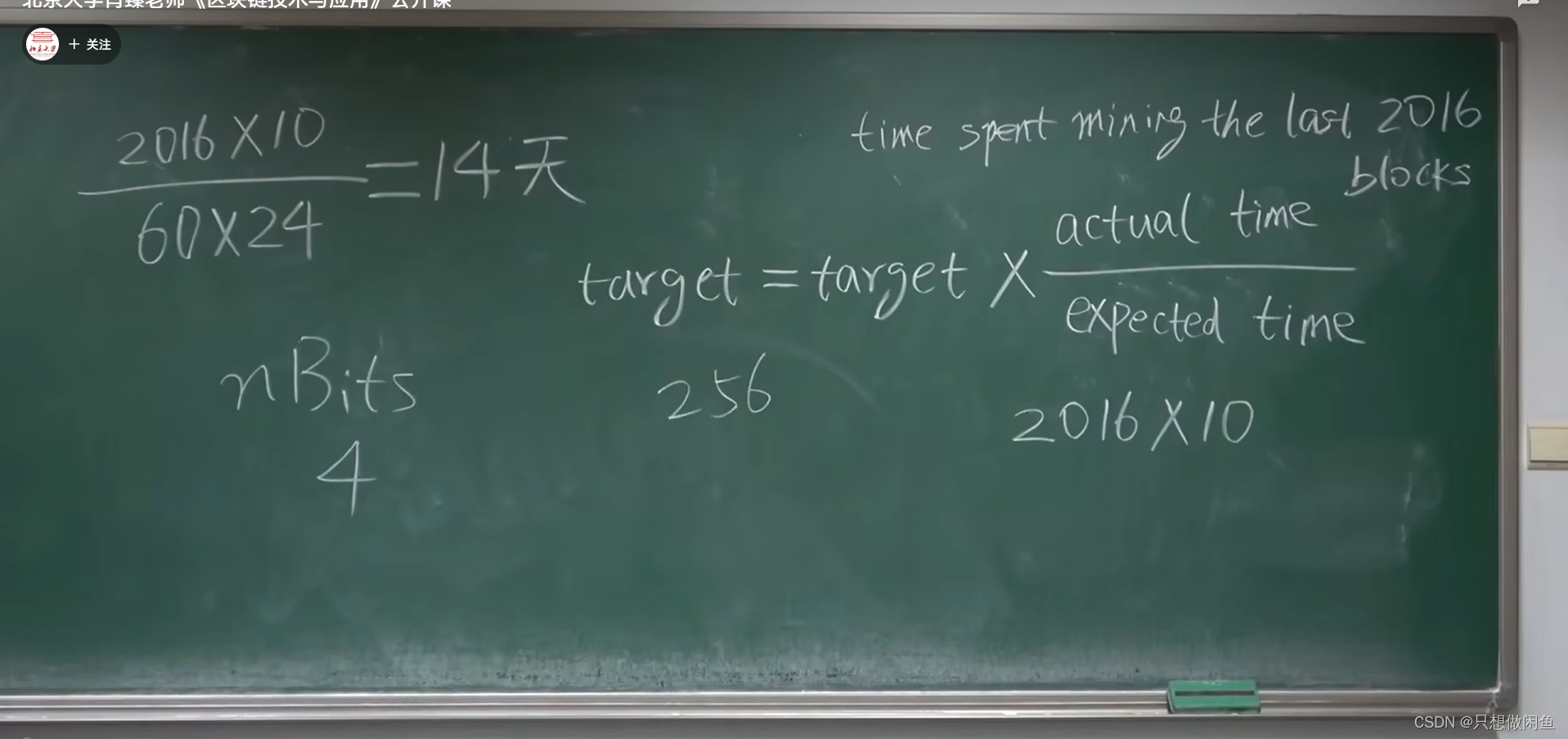大家好,今天我们来看看C语言中的一个重要知识,链表。当然大家可以先从名字中看出来。就是一些表格用链子连接。那么大家是否想到了我们以前学的数组,因为数组也是相连的呀。是吧。但是链表与数组还是有区别的,那么链表是什么有什么作用如何使用嘞等等。那么接下来我们就来康康吧。
单链表
那么我们先讲讲单链表。首先我们需要知道的是,链表并不是我们现实中所谓的链表,是实实在在连续的。我们C语言中的链表是像火车那样,用什么东西连接在一起的。那么我们这里就是在一节“车厢”中除了坐乘客(内容)还有就是编号(地址)。大家看一幅图可能了解的会更加清楚一些。
 并且我们知道火车车厢并不是规定的吧。就是以前的那种挂钩火车,在需要的时候可有多一点。不需要的时候减少一点也可以节约成本嘛。这也就表面我们在链表中可以根据我们的需要来申请节点,只需要我们指向就可以了。
并且我们知道火车车厢并不是规定的吧。就是以前的那种挂钩火车,在需要的时候可有多一点。不需要的时候减少一点也可以节约成本嘛。这也就表面我们在链表中可以根据我们的需要来申请节点,只需要我们指向就可以了。
然后大家是否有注意到图片上plist没有内容啊。而且它前面还没有任何东西啊。那这个是不是相当于火车的驾驶室啊。火车头。在c语言中这个特殊一点的东西叫做“哨兵位”。代表它更多的是来给我们指向方向位置的。我们大多不会对它干什么。这个哨兵位对我们后来的使用可是又恨到的作用的哦。大家注意一下。
定义单链表的节点
那么大家知道创建一个链表节点如同火车要先把壳造出来,然后在天东西进去,那么我们要先定义好节点的“壳”。那么我们先创建一个头文件Slist.h和源文件Slist.c。一个是定义数据的,讲文明需要用到的库函数的头文件全部放进去。然后需要定义的东西也放进去。那么我们肯定还需要一个实现代码的文件,那么我们再创建一个源文件text.h。来实现我们的代码。好但我们创建好了这些前置条件后,那么我们就来看看这个单链表的定义。
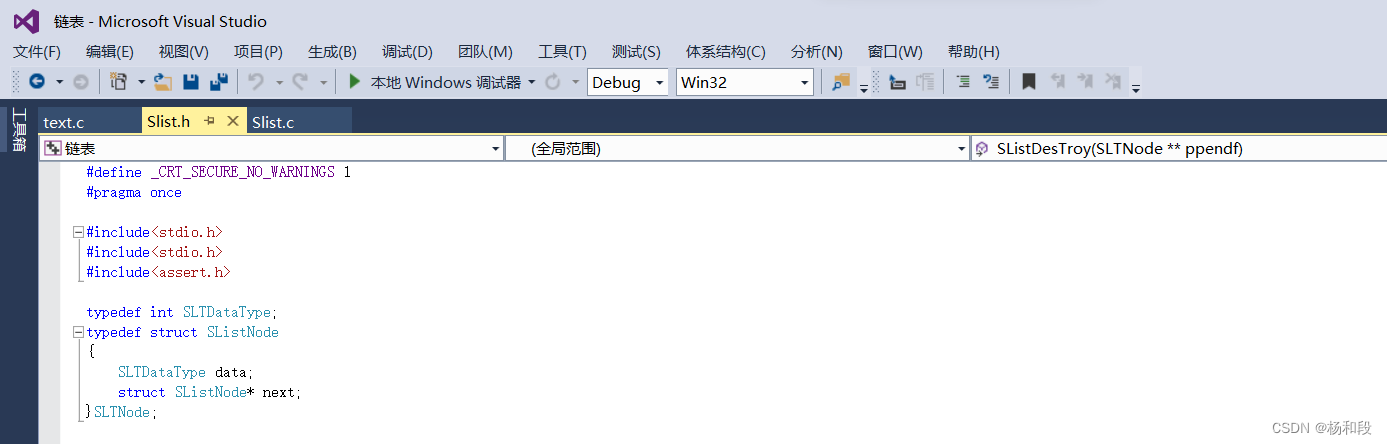
大家先看我们的主要知识,我们说单链表里面除了存放的内容外就是下一个节点的地址了。那么简单呀。我们创建这个结构体里面就只有要存放的内容和下一个节点的地址。好了。当我们知道结构体里面的内容后,那我们再看看其他的东西。我们除了开头的定义外。我们还使用了两个typedef将int和结构体的名字改了。当然结构体名字的修改只是为了我们后面方便书写。稍微有点说法的就是,我们将int改名了。这是为什么嘞。大家也知道我们把火车造出来后,谁会坐这个车嘞,大家都不知道,那么我们能不能说这个火车以后只有1米5的人会坐所以就把车顶改为1米6这肯定不合适,就是你造出来后,返现现在需要1米9了是不是要将车顶给取下来重新造啊。所以我们这里将int改个名字,当我们后面需要将结构体的内容类型改变的话我们就只需要修改开头的那个typedef就可以了。这里大家大概明白上面我们讲的知识了吧。
单链表的头插
当我们知道了单链的节点后,我们就来写写如何往里面写入数据吧。我们就先来一个简单的头插,那么头插是什么意思,我们肯定要知道吧。我们前面讲过plist这个哨兵位是没有数据的只是一个坐标,那么头插是否就是将plist指向的下一个节点改为我们想要的新节点且新节点的下一个指向是原本的plist->next。那么当大家稍微了解了一点这个头插什么意思后,那么我们在思考一下,我们要重新插入一个新的节点,是不是要改变原有的链表,那么我们是不是要传址过去,要是传值的话,不就是忙活一场竹篮打水一场空白干嘛。所以我们现在确定了我们要传地址给我们的头插代码。那么我们是不是还要将什么需要写入的内容是多少也写出来呀。所以我们这里就确定了。我们头插需要的两个内容。传地址和插入数据是多少。那么知道这些条件大家应该就知道如何实现这个指令了吧。

大家看了上面这个指令后发现咦什么是SLBuNode(x)啊。这个就是我们创建新节点。大家想想,我们肯定要先创建一个节点后才可以指向嘛。并且我们还有什么尾插,指定位置插入,是不是有很多时候都需要创建新节点,那么我们就写一个创建节点的代码以便于我们后面使用。

我们需要注意因为我们指向的节点肯定是一样的哇,所以返回类型是SLTNode,接收传来的是数据是多少。然后我们前面讲过动态内存开辟,malloc,realloc还有一个。但是malloc和另外一个在这里都不合适,为什么嘞,因为我们这里是创建一个没有任何关联且内容为空的节点那么是不是用malloc更加合适。然后我们判断是否创建成功。这个还是有比较好,毕竟你又不能保证有足够的空间给你创建。然后新知识:exit(1)。这个代码的头文件是<stdio.h>。然后这个歌代码的意思是看括号里面的数是真还是假,是真的话那么就会直接结束程序,不运行的。是假的话就不管。然后我们创建好了节点那么就需要给它赋值了,我们这里只给它传过来了个x。那么就确定了deta的值是多少。然后将指向的next指向为NULL。这里大家可能会想为什么要nxet指向NULL嘞,直接指向下一个节点这不更好吗?这里大家需要注意的时候,虽然我们可以传递下一个节点的地址过来,但是我们需要注意我们这里是知道我们写的是头插所以知道肯定有下一个节点,并且还可以看代码写出下一个节点的地址,但我们后面尾插嘞。还有其他的指令嘞。是不是就不能用了呀,所以我们这里只创建一个节点将data是多少确定了,指向的next让我们传回去,具体问题具体处理。当我们确定好后就return。
好,当我们知道写了一个都可以用的创建节点的代码后。回归主题。我们是不是要将新节点指向开始的头节点,然后将原本的位置直接给变为新节点,这样就头插好了,是吧。大家可以想一想,因为新节点指向原头节点,然后新节点直接将原头节点位置占了,那么哨兵位是不是指向新节点,然后新节点又指向原头结点。这样就完成了头插。
单链表的打印
当我们写了头插后,我们最好实现写一个代码然后实现一个代码,这样的话我们可以确定自己的错误在哪,那么我们最直接的是讲内容打印出来,是吧。那么我们如何打印嘞。我们是不是创建链表后节点指向下一个节点然后直接打印内容。那么我们是不是需要传递过来头节点。是吧,因为第一个节点我们需要打印,那么我们确定了传递的内容。然后我们就循环是吧。因为我们打印肯定就打印所有的节点,直到NULL的时候。那么循环就是while(头节点)这个就相当于while(头节点!=NULL)

这里我们头插了1,2,3。然后因为我们是插一次后打印一次那么所以最后的打印结果是3->2->1->NULL。结果是没问题的吧。
单链表的尾插
当我们实现了头插,那是不是尾插也要来一个,毕竟我们做事讲究有头有尾是吧,那么我们接下里下一个尾插代码。首先我们需要思考的是尾插理论上如何实现,我们可以想想,就是在最后的那个节点后再创建一个节点,然后让原尾节点指向新尾节点,新尾节点本来就指向NULL,所以我们不需要再来让新尾节点来指向了。所以我们的难题就是如何找到尾节点。但我们想一想是不是原尾节点是指向NULL的呀,那么我们只需要循环判断->next是否是NULL,如果不是那么就指向下一个节点,如果是就结束循环然后指向新尾节点。

这里有一个判断*ppendf是否为NULL,这是为什么嘞,大家想一想如果我们要插入的链表头节点就是NULL的话,我们上面的理论是不是就有问题了,如果我们开始传过来得就是NULL的话我们直接将头节点改为新节点不就好了。不知道大家是否能理解这个逻辑。
单链表的尾删
那么我们刚学习过尾插后,我们就趁热打铁把尾删学习了吧。我们还是先想一下理论。尾删要改变实际参数吧,那么肯定是传址吧。然后尾删那就是把倒数第二个节点指向NULL。然后释放最后一个节点。那么我们就需要找到这两个节点吧。所以我们要创建两个临时变量来表示这两个节点。那么以上是正常情况,既然是正常情况那么肯定就有特殊情况吧,如果传递过来的只有一个节点嘞如果开始就是指向的NULL,那么它不就是头节点也是尾节点了嘛。那么我们直接把这个释放就可以了,是吧。

单链表的头删
当我们学习过上面的代码逻辑后,头删应该就很简单了吧。我们只需要找到第二个节点然后把头节点释放掉,让第二个节点成为头节点就可以了。简单吧。

但是我们需要注意的是我们释放的顺序不能随便改变,如果是上面的代码直接修改的话,我们先修改为头节点,那么原头节点不就找不到了嘛,然后我们在释放岂不是释放错了。当然是还有其他办法的,如果大家感兴趣的话,可以在评论区里面评论。
单链表的指定前位置插入
好了,当我们写了头尾插入与删除后,那么我们来搞点不一样的,我们来指定位置前插入。这里大家可能会想啊。怎么是指定位置前插入啊。按顺序不应该是指定位置插入嘛。这个大家想想,指定位置插入,那就不是插入了,不就是修改嘛。思路就是找到了,然后将里面的deat改为想要的。这个很简单啊,我们只需要一个循环然后修改就可以。所以我就直接不写了。我在指定位置前后插入中写出寻找。然后一起使用。好了,那么我们现在来看看现在指定位置前插入。正常情况下,我们也是需要找到两个节点一个是指定位置和原指定位置前的节点,然后我们将新节点指向指定节点,原指定位置前的节点指向新节点,这样我们就完成插入了,是吧。所以这个的难度也就是我们需要找到两个节点。好,当我们了解了正常情况,那么特殊情况我们肯定也要熟悉,是吧。大家想想如果我们只有一个节点,头节点就是我们指定的位置怎么办,那这是不是就是我们前面写的头插啊。大家想一想。

单链表的指定后位置插入
有头有尾,那么指定位置后插入,不能少。但是我们看过指定位置前插入,指定位置后插入肯定也就不是什么问题了呀。我们只需要创建一个新节点,然后用传过来的节点指向新节点,新节点指向指定节点的下一个节点。哈哈哈,也许这样大家可能会懵圈。我们还是上代码,这样更直观一些。

单链表的指定位置删除
好了好了,兄弟们,当我们写了指定位置插入后,那么我们来写个指定位置删除,也是为了看起来舒服嘛。好,那么我们还是来写一下理论逻辑。我们是不是需要找到指定位置前的节点,然后将这个节点直接指向我们传过来的节点的下一个节点,就是跳过,知道吧,就是正常情况我们找到指定位置前的一个节点然后跳过指定节点直接指向指定节点的下一个就可以了。然后我们需要思考,我们特殊情况。如果就只有一个节点嘞。那是不是就是头删嘞。因为就一个节点呀
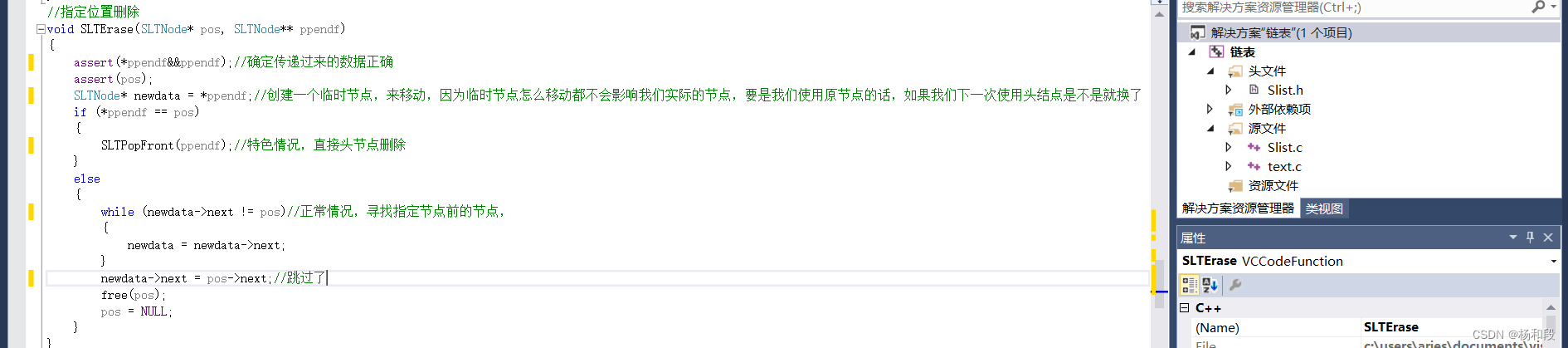

哈哈,我想这样可能会让大家看的更清楚一些吧,所以我们后面再学习链表的时候画图可以让我们的理解更加简单一些。(虽然我画的很丑,但是大家稍微看一下吧)
单链表的指定位置后删除
好,那么我们看了指定位置删除后,那么我们来讲讲指定位置后删除。那为什么不写指定位置前删除嘞,因为我觉得指定位置之前删除好像没什么作用吧,还不如我直接写一个指定位置删除嘞。因为我们只需要知道指定位置删除,这样还比较方便的嘞。指定位置后删除还是为了对称才写的。嘿嘿。好,那么我们还是先来逻辑。我们只需要找到指定节点后,让指定节点的下下节点来代替指定节点的下一个节点就可以,大家可以看一下下面的图片,可以让我们了解的更加清楚些。
 单链表的销毁
单链表的销毁
okok,现在我们写了这么多了,开头写了定义节点。虽然我们在途中写过删除,但是我们并没用写过销毁呀,因为我们开始写的都是一个一个删除的,所以我们接下来就写一个把全部的节点删除的代码。大家千万不要因为是把头节点删除就可以了哈,要是只删除头节点的话,那其它的节点就是野指针了啊。兄弟们,所以我们就是一个一个删除。好吧,那么我们直接来代码:
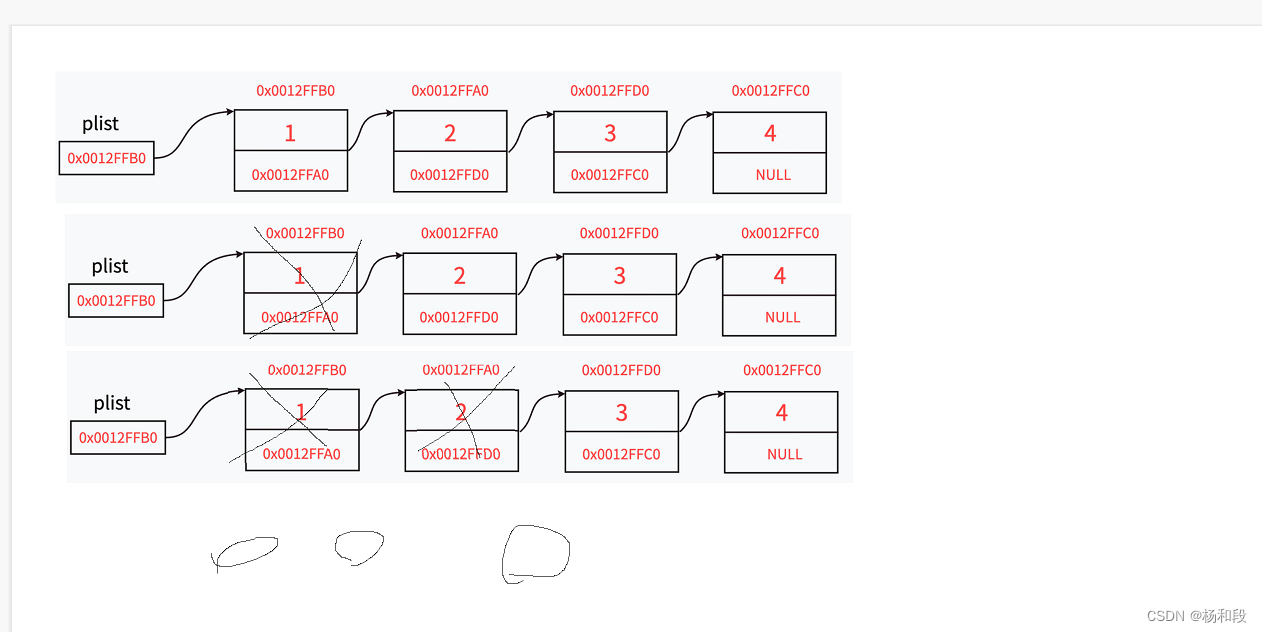

好了,这些就是单链表的一些使用方法了。当然还有很多的指令可以我们自己写,那么单链表我们就先写到这。
Slist.h
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<stdio.h>
#include<stdio.h>
#include<assert.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
void SLTPrint(SLTNode* pendf);
void SLTPushBack(SLTNode** ppendf, SLTDataType x);
void SLTPushFront(SLTNode** ppendf, SLTDataType x);
void SLTPopBack(SLTNode** ppendf);
void SLTPopFront(SLTNode** ppendf);
SLTNode* SLTFind(SLTNode* pendf, SLTDataType x);
void SLTInsert(SLTNode** ppendf, SLTDataType x, SLTNode* pos);
void SLTInsertAfter(SLTDataType x, SLTNode* pos);
void SLTErase(SLTNode* pos, SLTNode** ppendf);
void SLTEraseAfter(SLTNode* pos);
void SListDesTroy(SLTNode** ppendf);Slist.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"Slist.h"
//打印
void SLTPrint(SLTNode* pendf)
{
assert(pendf);
SLTNode* pucr = pendf;
while (pucr)
{
printf("%d->", pucr->data);
pucr=pucr->next;
}
printf("NULL\n");
}
//创建一个x的结点
SLTNode* SLBuyNode(SLTDataType x)
{
SLTNode* nemdata = (SLTNode*)malloc(sizeof(SLTNode));
if (nemdata == NULL)
{
perror("malloc fail");
exit(1);
}
nemdata->data = x;
nemdata->next = NULL;
return nemdata;
}
//尾插,写完了。但是还没理解,在看一遍
void SLTPushBack(SLTNode** ppendf, SLTDataType x)
{
SLTNode* newodata = SLBuyNode(x);
if (*ppendf == NULL)
{
*ppendf = newodata;
}
else
{
SLTNode* patil = *ppendf;
while (patil->next)
{
patil = patil->next;
}
patil->next = newodata;
}
}
//头插
void SLTPushFront(SLTNode** ppendf, SLTDataType x)
{
SLTNode* newodata = SLBuyNode(x);
newodata->next = *ppendf;
*ppendf = newodata;
}
//尾删
void SLTPopBack(SLTNode** ppend)
{
assert(*ppend&&ppend);//确定传来有节点
if ((*ppend)->next==NULL)//看是否是特殊情况,只有一个节点
{
free(*ppend);
*ppend = NULL;
}
else
{
SLTNode* pf = *ppend;//创建两个临时变量,方便下面找到倒数第一个和倒数第二个
SLTNode* yh = *ppend;
while (yh->next)//等同于while(yh->next!=NULL) 循环找
{//pf始终慢yh一步,所以当yh找到尾节点后,那么pf就是倒数第二个节点
pf = yh;
yh = yh->next;
}
free(yh);//释放尾节点,让倒数第二个指向BULL
yh = NULL;
pf->next = NULL;
}
}
//头删.相当于直接将*ppendf指向第二个。把最开始那个释放掉
void SLTPopFront(SLTNode** ppendf)
{
assert(*ppendf&&ppendf);//确定传来的数据正常
SLTNode* newdata = (*ppendf)->next;//找到第二个节点
free(*ppendf);//释放原头节点
*ppendf = newdata;//成为头节点
}
SLTNode* SLTFind(SLTNode* pendf, SLTDataType x)
{
SLTNode* yh = pendf;
while (yh)
{
if (yh->data == x)
{
return yh;
}
yh = yh->next;
}
return NULL;
}
//指定位置前插入数据
void SLTInsert(SLTNode** ppendf, SLTDataType x, SLTNode* pos)
{
assert(*ppendf&&ppendf);//确认传递过来的链表正常
assert(pos);//传过来额地址没错
SLTNode* newdata = SLBuyNode(x);//创建要插入的节点
SLTNode* yh = *ppendf;
if (*ppendf == pos)//判断是不是只有一个节点,如果是就头插
{
SLTPushFront(ppendf, pos);
}
else//正常情况,yh就是原指定位置前的节点
{
while (yh->next != pos)
{
yh = yh->next;
}//正式插入节点
newdata->next = pos;
yh->next = newdata;
}
}
//指定位置后插入数据
void SLTInsertAfter(SLTDataType x, SLTNode* pos)
{
assert(pos);//确认传过来的地址正确
SLTNode* newdata = SLBuyNode(x);//新节点
newdata->next = pos->next;//新节点的next指向指定节点的next
pos->next = newdata;//指定位置next变成新节点
}
//指定位置删除
void SLTErase(SLTNode* pos, SLTNode** ppendf)
{
assert(*ppendf&&ppendf);//确定传递过来的数据正确
assert(pos);
SLTNode* newdata = *ppendf;//创建一个临时节点,来移动,因为临时节点怎么移动都不会影响我们实际的节点,要是我们使用原节点的话,如果我们下一次使用头结点是不是就换了
if (*ppendf == pos)
{
SLTPopFront(ppendf);//特色情况,直接头节点删除
}
else
{
while (newdata->next != pos)//正常情况,寻找指定节点前的节点,
{
newdata = newdata->next;
}
newdata->next = pos->next;//跳过了
free(pos);
pos = NULL;
}
}
//删除指定位置之后
void SLTEraseAfter(SLTNode* pos)
{
assert(pos&&pos->next);//确定指定节点和下一个节点是有的
SLTNode* newdata = pos->next;//让 newdata成为被删除的那个
pos->next = newdata->next;//直接让pos->next变成 newdata的next
free(newdata);
newdata = NULL;
}
//链表的销毁
void SListDesTroy(SLTNode** ppendf)
{
assert(*ppendf&&ppendf);
SLTNode* newdata = *ppendf;
while (newdata)
{
SLTNode* yh = newdata->next;
free(newdata);
newdata = yh;
}
*ppendf = NULL;
}text.c
void yunxin1()
{
SLTNode* plist = NULL;
SLTPushFront(&plist, 1);
SLTPrint(plist);
SLTPushFront(&plist, 2);
SLTPrint(plist);
SLTPushFront(&plist, 3);
SLTPrint(plist);
//SLTPushBack(&plist, 1);
//SLTPushBack(&plist, 2);
//SLTPushBack(&plist, 3);
//SLTPushBack(&plist, 4);
//SLTPrint(plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPrint(plist);
//SLTNode*find= SLTFind(plist, 3);//寻找位置,以便于后面对有位置的操作需要
///*if (find == NULL)
//{
// printf("没找到\n");
//}
//else
//{
// printf("找到了\n");
//}
//SLTInsert(&plist, 1, find);
//SLTPrint(plist);*/
//SLTInsertAfter(5,find);
//SLTPrint(plist);
///*SLTErase(find, &plist);
//SLTPrint(plist);*/
//SLTEraseAfter(find);
//SLTPrint(plist);
}
int main()
{
yunxin1();
return 0;
}
这是实现指令的,大家其实可以直接写,大家看看,就可以了链表分类
当我们学习过上面最常见的单链表后,接下来看看其他的链表,首先就是我们有没有哨兵位,那么我们可以是一个区分,然后循不循环这又是一个区别。而且我们上面讲的都是单向的,就是前一个节点只是指向下一个节点的,但我们火车可以车厢到处走啊。那么我们就想到了双向吧。你指向我我也指向你,那么是不是就是双向啊。然后是否带头节点,是否循环有区分了。
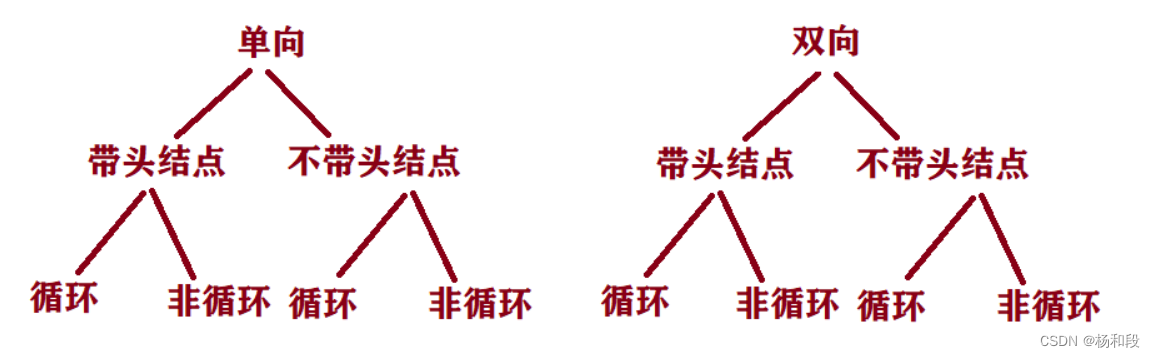
然后大家看看上面的图片就可以看到链表得分类了。然后我吗上面写的单链表是单向有节点不循环链表。而且大家可以很简单的区分开来,单向还是双向只需要看节点是否指向上一个节点和下一个节点。是否有一个节点指向头节点且无内容的,就可以区分是否带头节点了。然后我们看尾节点是否指向哨兵位那么我们就可以知道链表的分类。所以接下来我们讲讲双向带头节点循环链表。
双链表
好了,当我们看了上面的单链表和链表的分类后,我想大家对双链表的知识理解的会更简单一些。并且双链表的确比单链表简单,因为双链表是指向上一个和下一个节点的哇。好,那么我们还是来写实现的一些功能吧。
定义双链表的节点
那么我们老规矩,先来写一个定义双链表的节点代码。我们开始说了,双向链表就是可以指向下一个和上一个节点,在加上一个我们的数据。然后我们也是来写两个的源文件一个定义所有的头文件。但是这里我开始写的时候将实现的源文件和定义的源文件名字写错了,但是不影响我们使用,知识可能看的时候会让我们蒙一些下。

然后我们讲过我们这个是双向链表而且是带头且循环的。那么我们是不是还要创建一个哨兵位啊,所以我们再写一个初始化。来创建哨兵位。因为我们这里只是初始化,所以我们创建的哨兵位数据给了一个几乎不可能的数据。但是这里又有一个问题了,什么是LTBuyNode嘞。这个是我们创建节点的名字。因为我们后面实现指令的时候有很多机会使用创建节点的机会吧,所以我们直接先写写一些代码直接来表示这个,那么我们后面直接使用。就更方便了。

大家要注意哈,我们这个创建节点一定要在使用前。

好,我们这里讲过了定义链表,初始化(创建哨兵位),创建节点(方便我们后面需要创建节点使用)。那么我们在在后面实现效果的前奏已经准备好了。那么我们就来写写其他功能代码了吧。
双链表的尾插
好,这次我们从尾部开始,先来写一个尾插。这里我们尾插就是将头节点的prev指向新节点,然后原尾节点指向新节点,然后就是新节点的钱一个节点指向原尾节点,新节点的next指向哨兵位。这里大家可能会有一个疑问,啊。怎么哨兵位也开始用上了啊。开始单链表的时候哨兵位不就是一个吉祥物嘛。这是因为我们开头讲过我们这里是循环的,上面的单链表是不循环的,所以哨兵位是几乎用不上的。好了,解决这个问题那么我们来画个图来让我们更好的理解。
原链表:

插后:这里大家应该了解了吧,这是我们正常情况的时候,
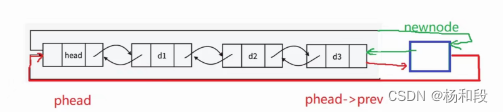
特殊情况:只有哨兵位

插入的话:不知道这样大家看一下是否有问题嘛,接上我们下面写的代码。


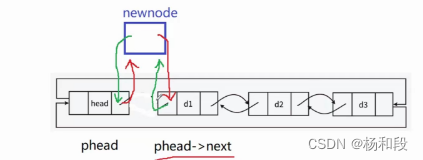
双链表的头插
好了我们尾插写过了,头插不能错过啊。然后头插的逻辑就是我们创建一个节点,让这个节点的成为phead和phead->next中间的节点。但是我们需要注意的是,我们指向的顺序不能有问题哦,如果我们先让phead的next变为新节点的话,我们是不是就找不到我们原本的phead->next节点了。所以这个大家也需要注意一下,我们替换的顺序也不是想谁先指向就先指向的,我们需要考虑是否会影响后面的指向。
这里我就不拿对比图了,我们直接看示意图。

双链表的尾删
okok,我们写了头尾插入后,接下来就是头尾删除了。因为我们是先写尾部,所以我们先来写尾删了。那么尾删我们是不是只要找到尾节点的前一个节点,然后让这个节点指向哨兵位。虽然这样想好像可以啊。但是我们是不是忘了要释放尾节点了啊。所以我们这样写的话是有问题的,那么我们就需要创建一个临时变量来记录尾节点,这样我们还可以更加方便找到尾节点的前一个节点,而且我们最后还不会丢失我们原尾节点的地址。


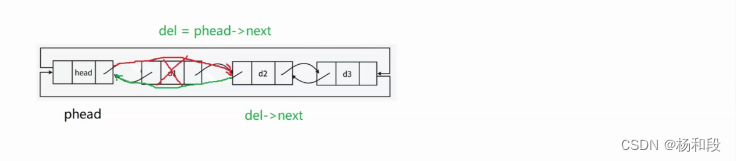
双链表的头删
那么我们写过尾删后,头删就简单了啊,我们只需要找到哨兵位的下一个节点然后哨兵位跳过这个节点,我们写一个临时变量来记录,这样不会止于我们找不到要删除的节点。

双链表的打印
我们写了这些代码后,肯定是需要验证的呀,那么我们还是直接打印出来,这样直观的看出来。我们写到这里都知道双链表是前后指向的,那么我们只是不用打印哨兵位,我们循环从哨兵位的前一个节点开始打印,然后一直走走到哨兵位的时候就停下来结束。LTNode* pucr = phead->next;while (pucr != phead)。很简单吧。那么我们直接上代码:

双链表的指定位置后插入
当我们学习过了头插,尾插后,我们的指定位置插入肯定也要来掺和一脚,那么我们先来写指定位置后的插入。那么我们思考一下逻辑不就是我们找到指定的节点,然后再创建一个新节点。我们让新节点先指向指定节点然后又将新节点的next指向下一个指定节点的next。然后就是在互相指向了。
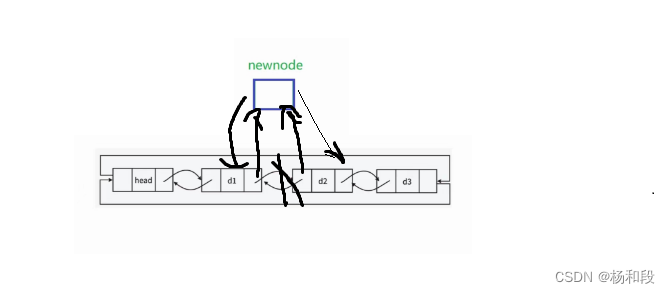

双链表的指定位置前插入
好的,我们写了指定位置后插入,那么指定位置前插入也要来搞一个啊。但是我们写这个完全是为了让我们的目录看起来更加舒服一些,实质性的代码与指定位置后插入相差无几的。大家只需要想一想就可以了。我们是不是就是将指定位置后的那个节点改为指定位置前就可以了。所以我们就直接上代码了吧。

双链表的指定位置删除
行,当我们写了指定位置插入后,我们现在写指定位置删除了。很简单吧,我们只需要用传来的节点,然后寻找到指定位置前和后的节点直接跳过指定节点就可以了。


双链表的销毁
我想大家如果看到现在应该对我们的双链表的理解应该就已经更加深刻了吧。那么我们就来写双链表的最后一个指令代码,双链表的销毁。但是我们还是要想一想,我们我们链表销毁,开始是不能动哨兵位的,所以我们开始就创建一个临时变量来成为头节点(哨兵位的前一个节点),然后依次销毁,直到我们循环再次到哨兵位的时候就停止了,那么我们就停止循环销毁,然后我们循环停止后,在自己手动销毁哨兵位。那么我们大概了解了逻辑了,我们直接上代码吧。

text.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"yinyong.h"
void LTPrint(LTNode* phead)
{
LTNode* pucr = phead->next;//应该临时变量,来移动,这样我们后面使用不会出现意想不到的问题
while (pucr != phead)
{
printf("%d->", pucr->data);
pucr = pucr->next;
}
printf("\n");
}
//创建节点
LTNode* LTBuyNode(LTDataType x)
{
LTNode* node = (LTNode*)malloc(sizeof(LTNode));//向动态内存申请LTNode的字节
if (node == NULL)//有可能内存不够,所以判断是否申请成功
{
perror("malloc\n");
exit(1);
}
node->data = x;//内容确定
node->prev =node->next= node;//因为我们只是创建节点,所以我们就创建一个自己指向自己的节点
return node;//返回创建的节点
}
//初始化
void LTInit(LTNode** pphend)
{
//创建哨兵位
*pphend = LTBuyNode(-1);
}
//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newdata = LTBuyNode(x);//创建节点
newdata->prev = phead->prev;//phead是哨兵位
newdata->next = phead;
phead->prev->next = newdata;
phead->prev = newdata;
}
//头插
void LTPushFront(LTNode* phead, LTDataType x)
{
assert(phead);//确认链表正确性
LTNode* newdata = LTBuyNode(x);//创建节点
newdata->next = phead->next;//先新节点的next指向头节点的nxet
newdata->prev = phead;//prev指向头节点
phead->next->prev = newdata;//原头节点指向新节点。然后头节点指向新节点。相当于替换原节点了
phead->next = newdata;
}
//尾删
void LTPopBack(LTNode* phead)
{
assert(phead&&phead->next!=phead);//确认链表和链表不是只有哨兵位
LTNode* del = phead->prev;//临时变量记录原尾节点
del->prev->next = phead;//尾节点的前一个节点指向哨兵位
phead->prev = del->prev;//哨兵位的上一个节点指向尾节的前一个节点。这样我们的尾删就结束了
free(del);
del = NULL;
}
//头删
void LTPopFront(LTNode* phead)
{
assert(phead&&phead->next != phead);//确认链表和链表不是只有哨兵位
LTNode* del = phead->next;//临时变量记录原头节点
phead->next = del->next;//哨兵位的next指向del的下一个节点
del->next->prev = phead;//del的下一个节点的上一个节点指向哨兵位
free(del);//最后释放del
del = NULL;
}
LTNode* zhao(LTNode* phead, LTDataType x)
{
LTNode* ps = phead->next;
while (ps != phead)
{
if (ps->data == x)
{
return ps;
}
ps = ps->next;
}
return NULL;
}
//指定位置之后插入
void LTInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* node = LTBuyNode(x);//创建节点
node->prev = pos;//新节点的上一个节点指向指定节点
node->next = pos->next;//新节点的next指向指点节点的next
pos->next->prev = node;//然后就是指定节点与原指定节点后的节点指向新节点了
pos->next = node;
}
//删除指定节点
void LTErase(LTNode* pos)
{
assert(pos);
pos->next->prev = pos->prev;
pos->prev->next = pos->next;
free(pos);
pos = NULL;
}
//链表的销毁
void LTDesTroy(LTNode* phead)
{
assert(phead);
LTNode* node = phead->next;
while (node != phead)
{
LTNode* del = node->next;
free(node);
node = NULL;
}
free(phead);
phead = NULL;
}
//因为传的一级指针所以,有些东西没有销毁完全,有些东西需要直接手动删除
//find和plist
//指定位置之前插入
void LTInqian(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* node = LTBuyNode(x);
node->next = pos;
node->prev = pos->prev;
pos->prev->next = node;
pos->prev = node;
}yinyong.h
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;//数据内容
struct ListNode* next;//指向下一个节点
struct ListNode* prev;//指向上一个节点
}LTNode;
void LTInit(LTNode** pphend);//初始化
void LTPushBack(LTNode* phead, LTDataType x);//尾插
void LTPushFront(LTNode* phead, LTDataType x);//头插
void LTPopBack(LTNode* phead);//尾删
void LTPopFront(LTNode* phead);//头删
void LTInsert(LTNode* pos, LTDataType x);//指定位置之后插入
void LTInqian(LTNode* pos, LTDataType x);
void LTErase(LTNode* pos);//删除指定节点
void LTDesTroy(LTNode* phead);//链表的销毁
void LTPrint(LTNode* phead);//打印
yinyong.c
#define _CRT_SECURE_NO_WARNINGS 1
#include"yinyong.h"
void yong()
{
LTNode* plist = NULL;
LTInit(&plist);
LTPushBack(plist, 1);
LTPrint(plist);
LTPushBack(plist, 2);
LTPrint(plist);
LTPushBack(plist, 3);
LTPrint(plist);
LTPopFront(plist);
LTPrint(plist);
LTNode* find = zhao(plist, 2);
if (find == NULL)
{
printf("没找到\n");
}
else
{
printf("找到了\n");
}
/*LTInsert(find, 5);
LTPrint(plist);
LTErase(find);
LTPrint(plist);*/
LTInqian(find, 4);
LTPrint(plist);
}
int main()
{
yong();
return 0;
}总结
我们这里写的链表其实是没有实质性的链接的,是我们认为的创建结构体然后相连的。所以我们在使用或者学习链表的时候画图可以让我们理解起来更加简单。这也是一个很好的方法。然后我们在使用链表的时候要注意逻辑性,不要依靠自己怎么想,要考虑实际情况的。那么今天的分享就到这里,希望上面的分享就可以帮助到各位。